Lecture 6. Protein primary structure
Friday 16 September 2016
Primary structure of polypeptides and proteins. Polypeptide diversity. Protein purification and analysis. Protein sequencing.
Reading: VVP4e - Ch.5, pp.93-123.
Summary
We begin an exploration of protein structure and function with a ground level view of proteins and their experimental characterization. Proteins are biological polymers made up of amino acid monomers linked together via peptide bonds. Hence, another term used in this context is polypeptide. The structure of proteins is described in a hierarchical manner, and the lowest level of this hierarchy is the primary structure, or amino acid sequence, of a given polypeptide chain. We may well consider the primary structure of a protein to be its covalent structure - i.e. what atoms are connected together in covalent bonds as a macromolecule. In this way, we can incorporate any important post-translational modifications to a polypeptide chain under the umbrella of primary structure.

As an example, consider insulin. In humans, the mature, active form of insulin is secreted by the pancreas and circulates systemically and acts on peripheral organs to stimulate the uptake and storage of carbohydrates and fats (lipids). The mature insulin molecule is not directly produced by ribosomal protein synthesis. Instead it is synthesized by ribosomes as a single polypeptide chain of 110 amino acids that is targeted to the endoplasmic reticulum (ER) by the N-terminal portion of the nascent polypeptide chain, termed the signal peptide. The signal peptide is cleaved, and the remaining chain undergoes folding and oxidation of cysteine residues to form disulfide bonds. It is worth noting here that intracellular, cytosolic proteins are maintained in a relatively reduced environment, and disulfide bonding is not very common. Extracellular proteins, are exposed to relatively more oxidizing conditions, which promotes disulfide bonding. Further processing in secretory vesicles results in the removal of an internal section of the polypeptide chain, yielding mature insulin which consists of two disulfide-linked polypeptide chains, an A chain of 21 amino acids and the B chain of 30 amino acids, as shown in the figure. Thus, the covalent structure of insulin - a rather small protein - technically differs from the amino acid sequence, in that the latter does not convey the conversion of cysteine residues to specific pairs of disulfide-linked residues (the disulfide-linked pair is occasionally referred to as a cystine residue). Analogously, the post-translational modifications of individual amino acids - such as glycosylations or phosphorylations - are not explicitly indicated by the amino acid sequence. The processing and modifications of polypeptide chains is in most cases of crucial importance to the biologic functional roles they play, as the insulin example illustrates.
In Ch.5 of our text, entitled "Proteins: Primary Structure", the subject matter is treated under four section headings: Polypeptide diversity, protein purification and analysis, protein sequencing, and protein evolution. In this lecture summary, my aim is not to reproduce what is in the text, but to provide context and commentary, as well as an emphasis on selected important concepts.
Polypeptide diversity
As we will subsequently see, the amino acid sequence of a polypeptide chain determines its structure at the highest level, i.e. its tertiary structure or three-dimensional conformation. The tertiary structure of a polypeptide chain, in turn, is inextricably linked to its biological function. Our shorthand expression for this principle is that structure determines function.
Protein purification and analysis
In order to study a protein, it is typically necessary from an experimental point of view to produce a sample of the protein in a reasonably pure form. Our text accordingly discusses the laboratory methods for protein purification. It is relevant and helpful to distinguish between preparative and analytical methods of fractionation that are used to produce samples that are enriched or purified with respect to a given target protein. This distinction is a matter of scale, with preparative methods, principally chromatography, yielding a larger scale sample of a protein useful for further characterization or study. We'll consider large scale to be on the order of milligram (mg) quantities or more. For example, an enzyme sample produced on a preparative scale is used for kinetic and inhibition studies, or a given protein is produced in quantity for crystallization trials that are a necessary prerequisite for determination of its tertiary structure by the method of X-ray crystallography. On the other hand, analytical methods, such as gel electrophoresis and capillary electrophoresis yield very small quantities. Analytical-scale methods are useful as means of assessing the progress of a preparative-scale method of purification, or as the starting point for further analysis that can be performed using minute quantities of material, such as picomole-scale peptide sequencing by Edman degradation, or mass spectrometry measurements. The increasing technological sophistication of methods used for the characterization of protein samples, particularly their sensitivity, has made it possible to obtain a wealth of information from analytical-scale preparations.
Preparative methods: Salting in/salting out; Chromatography (ion exchange, hydrophobic interaction, gel filtration, affinity).
Purifying a protein requires a strategy.
Salting out separates proteins by their solubility.
Chromatography involves interaction with mobile and stationary phases
Electrophoresis separates molecules according to charge and size
Both ion exchange chromatography and isoelectric focusing depend on the charge of the species being fractionated. Here, we review the principle of the variation of charge of polyelectrolyte species such as a polypeptide chains with the pH of their surrounding environment.
- Definition: The pI, or isoelectric point, of a polyelectrolyte is the pH at which the net charge on the molecule is zero.
- If pH > pI, then the molecule is negatively charged (e.g. acidic proteins have pI < 7)
- If pH < pI, the molecule will be positively charged (e.g. basic proteins have pI > 7)
The figure below illustrates these ideas on how the charge on a protein would vary with the "ambient" pH of the medium of which it is a component.
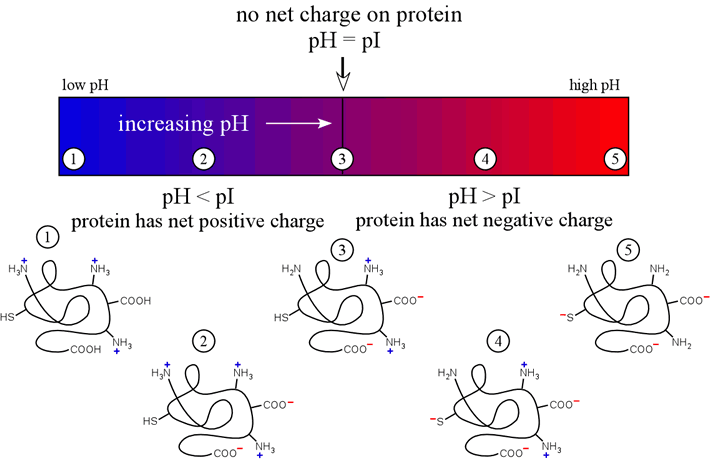
The above diagram represents a polypeptide chain with a pI value near neutrality. We ought to also consider how polypeptide pI varies generally with amino acid composition.
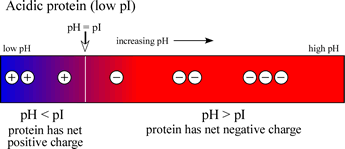
If a protein contains a high content of acidic residues, these being aspartate and glutamate, and a relatively low content of basic residues (lysine, arginine), then the pI value will be in the acidic range (<7). The charge vs. pH diagram for such an acidic protein is shown at left.
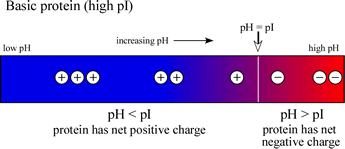
If, on the other hand, a protein contains a high content of basic residues and a relatively low content of acidic residues, then the pI value will be in the basic range (>7), and the diagram at right will be representative of such a case.
Note that an acidic (low pI) protein will carry a net negative charge at a neutral pH, while a basic (high pI) protein will bear a net positive charge at a neutral pH.